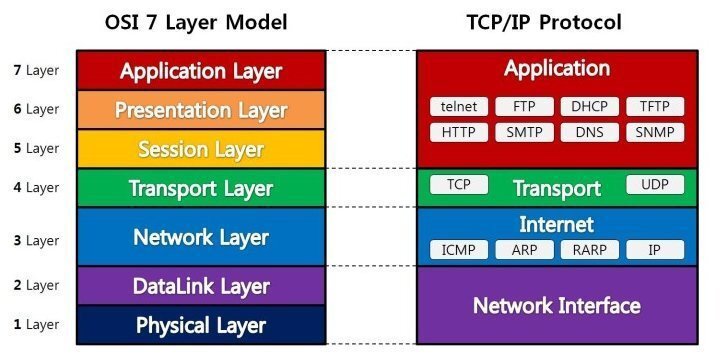
OSI 7계층
- OSI 모형(Open Systems Interconnection Reference Model)은 국제표준화기구(ISO)에서 개발한 모델로, 컴퓨터 네트워크 프로토콜 디자인과 통신을 계층으로 나누어 설명한 것
- 개방형 시스템 상호 연결 모델의 표준
- 실제 인터넷에서 사용되는 TCP/IP 는 OSI 참조 모델을 기반으로 상업적이고 실무적으로 이용될 수 있도록 단순화한 것임
- 초기 여러 정보 통신 업체 장비들은 자신의 업체 장비들끼리만 연결이 되어 호환성이 없었음
- 모든 시스템들의 상호 연결에 있어 문제없도록 표준을 정한것이 OSI 7계층
- 표준(호환성)과 학습도구에 의미로 제작
작동 원리
- 전송 시 7계층에서 1계층으로 각각의 층마다 인식할 수 있어야 하는 헤더를 붙임(캡슐화)
- 수신 시 1계층에서 7계층으로 헤더를 떼어냄(디캡슐화)
- 물리계층에서 1, 0 의 신호가 되어 전송매체 (동축케이블, 광섬유 등)을 통해 전송
물리 계층
- 전기적, 기계적 특성을 이용해 데이터를 전송
- 데이터 단위 : Bit
- 프로토콜 : RS-232, RS-449
- 장비 : 케이블, 리피터, 허브
데이터링크 계층
- 물리적 연결(Point to Point)을 통해 두 장치간의 신뢰성 있는 정보 전달, MAC 주소를 통해 목적지를 찾아간다
오류 검출, 오류제어, 흐름제어기능 수행
- 데이터 단위 : Frame,
- 프로토콜 : Ethernet, PPP, HDLC
- 장비 : 브리지, 스위치
네트워크 계층
- 중계 노드를 통해 어떻게 경로를 설정할지 담당
라우팅 알고리즘을 통한 최적의 경로 설정가능, 주소로 IP를 사용
- 데이터 단위 : Packet
- 프로토콜 : IP, RIP, ARP, ICMP
- 장비 : 라우터, L3
전송계층
- 데이터 전송을 위해 헤더의 포트번호를 이용한다.
패킷전송 유효, 신뢰성있는 통신 보장, 주소설정, 오류 제어, 흐름제어, 다중화 수행
- 데이터 단위 : Segment / Datagram
- 프로토콜 : TCP / UDP
- 장비 : Gateway, L4 스위치
세션계층
- 응용 프로그램간의 논리적인 연결(세션) 생성 및 제어를 담당
- 데이터 단위 : Data, Message
- 프로토콜 : NetBIOS, SSH
표현계층
- 데이터를 어떻게 표현할지 정하는 역할(데이터 암/복호화, 데이터 압축, 인코딩)
- 데이터 단위 : Data
- 프로토콜 : JPG, MPEG, AFP, PAP
응용계층
- 인터페이스를 통해 사용자와
- 데이터 단위 : Data
- 프로토콜 : HTTP, FTP, SMTP, DNS
https://better-together.tistory.com/134
https://hahahoho5915.tistory.com/12
TCP / UDP
OSI 7계층 중 전송계층에서 사용하는 프로토콜
전송계층이 하는 역할? IP에 의해 전달되는 패킷의 오류를 검사하고 재전송 요구 등의 제어를 담당
포트번호를 이용하여 주소를 지정하며, 데이터 오류 검사를 위한 체크섬이 존재한다.
신뢰성이 요구되는 전송을 해야 할 때 TCP를 사용 간단한 데이터를 빠른 속도로 전송하고자 할 때는 UDP를 사용
| TCP(Transmission Control Protocol) | UDP(User Datagram Protocol) |
| - TCP 세그먼트 패킷 - 연결지향형 프로토콜(Connection-oriented protocol) 가상 회선 방식을 제공 - 바이트 스트림을 통한 연결 - 연결을 3-way handshaking 해제는 4-way handshaking - 흐름제어 및 혼잡제어가 가능 - 높은 신뢰성을 보장 - 순서를 보장하며 UDP보다 속도가 느리다 - 전이중(Full-Duplex), 점대점(Point to Point) 방식을 사용 (멀티캐스팅, 브로드 캐스팅 지원X) - HTTP, Email, File transfer에서 사용 |
- UDP 데이터그램 패킷 - 비 연결지향형(Connection-less protocol) 프로토콜 - 메세지 스트림을 통한 연결 - 흐름제어와 혼잡제어를 지원하지 않음 - 데이터 전송을 보장하지 않음 - 순서가 보장되지 않으며 상대적으로 빠름 - DNS, Broadcasting /도메인, 실시간 동영상 서비스에서 사용 |
※ 흐름제어와 혼잡제어
흐름제어 : 데이터 처리 속도를 조절, 수신자의 버퍼 오버 플로우 방지
혼잡제어 : 네트워크 내 패킷 수가 넘치게 증가하지 않도록 방지
※ 전이중과 점대점 방식
전이중 : 전송이 양방향으로 동시에 발생
점대점 : 각 연결이 정확히 2개의 종단점을 가짐
※ 신뢰성이 높다는 건 어떤 의미일까?
어플리케이션 프로세스 사이에 전달되는 데이터가 "하나도 유실되지 않고" 전달 되는 것
즉, 패킷이 에러(변형)와 유실이 없이 전달이 되어야 한다.
RDT(Reliable data transfer) 프로토콜로 확인하는 방법(2.1)
1) Sender가 패킷을 보낸다
- 보낼 때마다 패킷에 시퀀스 번호(Sequence number)를 붙인다
2) Receiver는 패킷 전송이 정상적으로 전달되었는지 확인 (에러감지, 피드백)
- 체크섬으로 데이터의 무결성 확인
- 패킷을 받을 때마다 ACKs 로 피드백 전송 / 에러가 나면 NAKs전송
3) Sender는 확인되면 다음 패킷을 전송 (재전송)
- ACK를 받으면 확인후 다음 패킷 전송
- NAK를 받으면 현재 패킷을 재전송
패킷이 유실된다면?!?
- 일정 시간동안 피드백이 오지 않으면 타임아웃(Timeout)으로 간주하고 데이터를 재전송
- 그 타이머를 어떻게 지정해야 할까?
짧으면? 빠르게 유실 상황 복구 / 정상 전달되었음에도 중복된 패킷이 전송될 수 있음(네트워크 오버헤드 많아짐)
길면? 네트워크 오버헤드 예방 가능 / 유싱상황에 대한 반응이 느리다
참고: https://dev-nicitis.tistory.com/27
※ 3-Way handshaking
정확한 전송을 보장하기 위해 상대방과 사전에 세션에 수립하는 과정
SYN(연결요청 플래그) / ACK(응답플래그) / FIN(연결종료 플래그)
1. A가 SYN(연결요청 메세지)를 B에게 보내고 SYN_SENT 상태로 대기한다. A 포트는 CLOSED상태. B포트는 LISTEN상태
2. B는 포트를 SYN_RCVD 상태로 바꾸고 A에게 SYN과 응답 ACK를 보낸다.
3. SYN과 응답 ACK을 받은 A는 포트를 ESTABLISHED 상태로 변경하고 서버에게 응답 ACK를 보낸다.
4. 응답 ACK를 받은 서버는 포트를 ESTABLISHED 상태로 변경한다.
※ 4-Way handshaking
1. A 는 B에게 FIN을 보내고 FIN_WAIT1 상태로 대기한다.
2. B는 CLOSE_WAIT으로 상태를 바꾸고 응답 ACK를 전달한다.
동시에 해당 포트에 연결되어 있는 어플리케이션에게 close()를 요청한다.
3. ACK를 받은 A는 상태를 FIN_WAIT2로 변경한다.
4. close() 요청을 받은 B는 종료 프로세스를 진행하고 FIN을 A에게 보내 LAST_ACK 상태로 바꾼다.
5. FIN을 받은 A는 ACK를 서버에 다시 전송하고 TIME_WAIT으로 상태를 바꾼다.
TIME_WAIT에서 일정 시간이 지나면 CLOSED된다. ACK를 받은 B도 포트를 CLOSED로 닫는다.
참고:
https://sh-safer.tistory.com/146
https://gmlwjd9405.github.io/2018/09/19/tcp-connection.html
HTTP와 HTTPS
웹브라우저(Client)와 서버(Server)간의 웹페이지같은 자원을 주고 받을 때 쓰는 통신 규약HTTP으로 데이터를 전송할 때 암호화 과정을 거치지 않고 평문으로 보내기 때문에 중간에 패킷을 가로챌 수 있고, 수정할 수 있습니다. 따라서 보안이 취약해짐
이를 보완하기 위해 나온 것이 HTTPS
- 중간에 SSL(Secure Sockets Layer)이라는 보안계층을 거쳐서 패킷을 암호화
- 443번 포트 사용
- 제3자 인증, 공개키 암호화, 비밀키 암호화
HTTPS 연결
1. 클라이언트(브라우저)가 서버로 최초 연결 시도를 함
2. 서버는 공개키(엄밀히는 인증서)를 브라우저에게 넘겨줌
3. 브라우저는 인증서의 유효성을 검사하고 세션키를 발급함
4. 브라우저는 세션키를 보관하며 추가로 서버의 공개키로 세션키를 암호화하여 서버로 전송함
5. 서버는 개인키로 암호화된 세션키를 복호화하여 세션키를 얻음
6. 클라이언트와 서버는 동일한 세션키를 공유하므로 데이터를 전달할 때 세션키로 암호화/복호화를 진행함
HTTPS 발급과정
위의 과정에서 추가로 살펴봐야 할 부분은 서버가 비대칭키를 발급받는 과정이다. 서버는 클라이언트와 세션키를 공유하기 위한 공개키를 생성해야 하는데, 일반적으로는 인증된 기관(Certificate Authority)에 공개키를 전송하여 인증서를 발급받는다. 자세한 과정은 다음과 같다.
- A기업은 HTTP 기반의 애플리케이션에 HTTPS를 적용하기 위해 공개키/개인키를 발급함
- CA 기업에게 돈을 지불하고, 공개키를 저장하는 인증서의 발급을 요청함
- CA 기업은 CA기업의 이름, 서버의 공개키, 서버의 정보 등을 기반으로 인증서를 생성하고, CA 기업의 개인키로 암호화하여 A기업에게 이를 제공함
- A기업은 클라이언트에게 암호화된 인증서를 제공함
- 브라우저는 CA기업의 공개키를 미리 다운받아 갖고 있어, 암호화된 인증서를 복호화함
- 암호화된 인증서를 복호화하여 얻은 A기업의 공개키로 세션키를 공유함
https://mangkyu.tistory.com/98
https://jeongupark-study-house.tistory.com/79
※ SSL 암호화 통신 이라고도 합니다. SSL 암호화 통신은 공개키 암호화 방식이라는 알고리즘을 통해 구현
Netscape가 1995년 처음으로 개발했습니다. SSL은 현재 사용 중인 TLS 암호화의 전신입니다.
FTP
"File Transfer Protocol"의 약자로 인터넷을 통해 파일을 전송하는 방법
- FTP 서버로부터 파일을 '받거나', FTP 서버로 파일을 '보냅니다'.
- FTP는 다른 프로토콜들과 다르게 포트(port) 번호를 기본 두 개 사용 한다.
21번으로 클라이언트와 서버 사이의 명령, 제어 등을 송수신하는 제어 포트
20번으로 클라이언트와 서버 사이의 직접적인 파일 송 수신을 담당하는 데이터 포트
DNS
Domain Name System
웹사이트의 IP주소와 도메인 주소를 이어주는 시스템
IP주소를 직접 치지 않고 도메인 이름을 입력해도 해당 웹페이지로 이동하게 한다.
전 세계 분산형 데이터 베이스 구조로 동작
DNS 는 흔히 전화번호부에 비유되는데 이는 트리 형태로 구성이 되어 있다. Root) 아래에 역 트리 구조로 구성되어 있다.
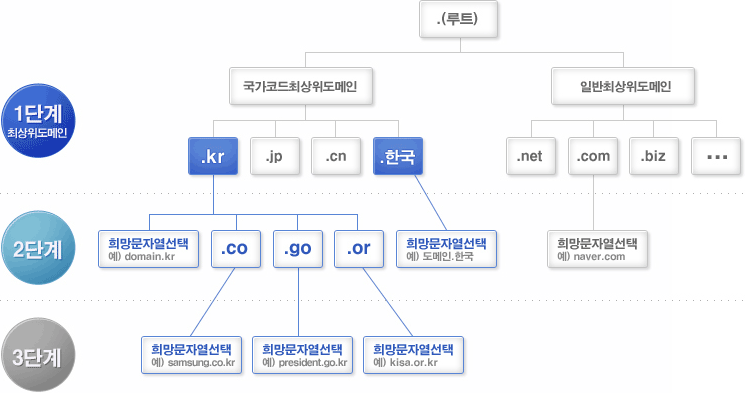
루트 도메인 바로 아래의 단계를 1단계 도메인 또는 최상위도메인(TLD, Top Level Doamin)이라고 부르며, 그 다음 단계를 2단계 도메인(SLD, Second Level Domailn)으로 구분
1단계 도메인은 일반최상위도메인(gTLD: Generic Top Level Domain)과 국가최상위도메인(ccTLD: Country Code Top Level Domain)로 구분할 수 있으며 여기서 일반최상위도메인은 다시 스폰서도메인(Sponsored TLD)과 언스폰서도메인(Unsponsored TLD)으로 구분
https://kyun2da.dev/CS/dns%EB%9E%80-%EB%AC%B4%EC%97%87%EC%9D%B8%EA%B0%80/
메모리의 공간
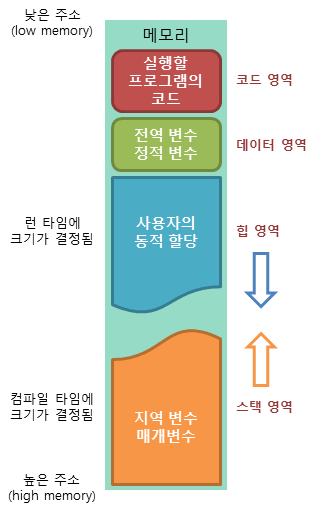
코드 영역
실행할 프로그램의 코드가 기계어 명령 형태로 변한되어 저장되는 영역
CPU는 코드 영역에 저장된 명령어를 하나씩 가져와서 처리
컴파일 타임에 결정되고 중간에 코드를 바꿀수 없게 Read-Only로 됨
데이터 영역
프로그램의 전역 변수와 정적 변수 즉, 프로그램이 사용하는 데이터가 저장되는 영역
프로그램의 시작과 함께 할당이 되고, 프로그램이 종료되면 소멸
힙 영역
사용자가 직접 관리가 가능한 메모리 영역, 동적할당과 해제가 가능함
메모리의 낮은 주소에서 높은 주소 방향으로 할당ㄷ
런타임에 결정
스택영역
heap영역의 오프젝트를 가리키는 레퍼런스 변수가 stack에 올라감
컴파일시 크기가 할당이 됨
함수의 호출과 함께 할당이 되며, 함수의 호출이 완료되면 소멸
함수의 호출과 관련있는 지역함수와 매개변수(파라미터) 리턴값이 저장
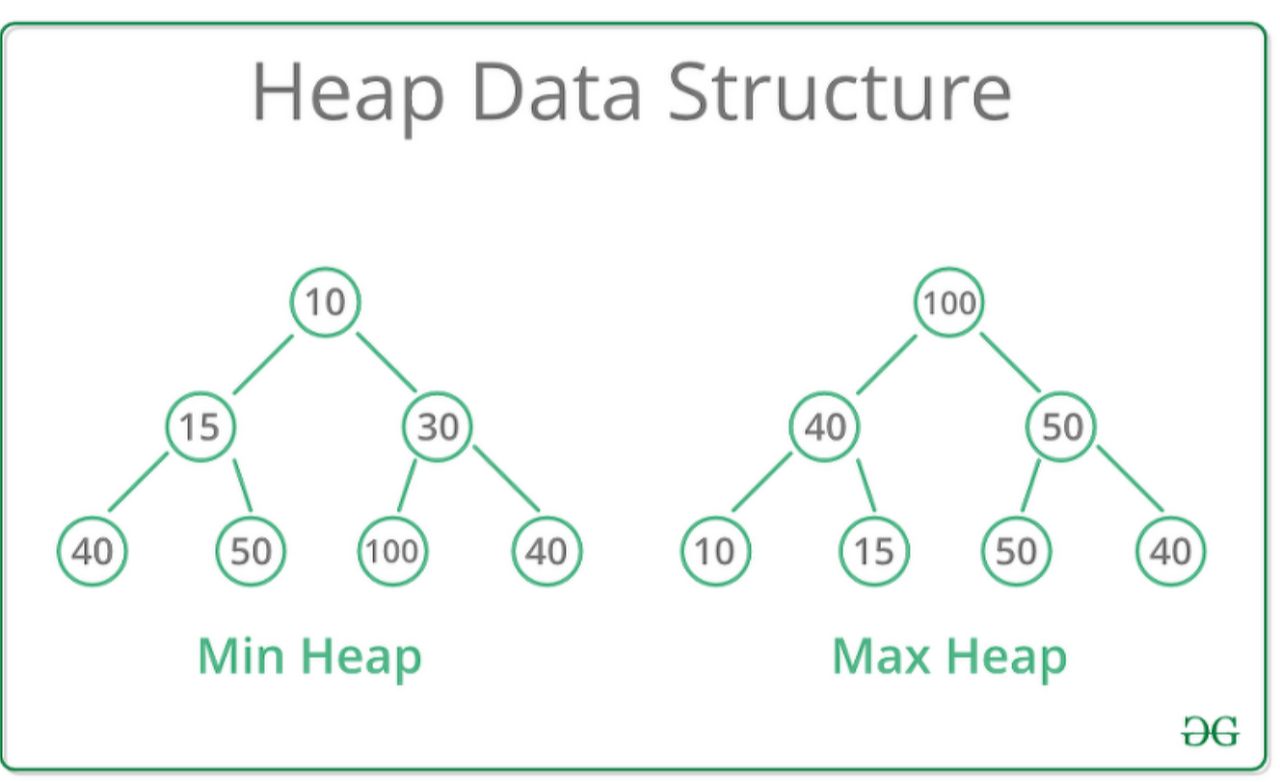
Heap
- 최댓값 및 최솟값을 찾아내는 연산을 빠르게 하기 위해 고안된 완전이진트리(complete binary tree)를 기본으로 한 자료구조
- 최댓값이 맨 위인 힙을 max-heap, 최솟값이 맨 위인 힙을 min-heap이라고 한다.
- 힙은 항상 큰 값이 상위 레벨에 있고 작은 값이 하위 레벨에 있어야 한다.
https://algoroot.tistory.com/69?category=997035
Stack
- LIFO(Last in, Last out) 원칙으로 만들어진 자료구조 > 나중에 들어온 데이터가 먼저 나간다.
- 함수 실행 콘텍스트들이 쌓이는 Call stack과 브라우저의 방문 기록이 쌓이는 History stack이 대표적이다.
- 서로 관계가 있는 여러 작업을 연달아 수행하면서 이전의 작업 내용을 저장해 둘 필요가 있을 때 널리 사용된다.
- 스택(Stack)이 비어있을 때 stack.pop을 시도하는 것을 stack underflow라고 하고 스택(Stack)의 크기가 비어있을 때 stack.push를 시도하면 stack overflow가 발생한다.
- 재귀 알고리즘 / 웹 브라우저 방문기록 / 실행취소 등 이전의 작업 내용을 저장해 둘 필요가 있을 때 널리 사용
class Stack {
constructor() {
this._arr = [];
}
push(item) {
this._arr.push(item);
}
pop() {
return this._arr.pop();
}
peek() {
return this._arr[this._arr.length - 1];
}
}
const stack = new Stack();
stack.push(1);
stack.push(2);
stack.push(3);
stack.pop(); // 3출처: https://algoroot.tistory.com/54 [Algoroot's space:티스토리]
Queue 자료 구조
- 데이터를 집어넣을 수 있는 선형(linear) 자료형입니다.
- 먼저 집어넣은 데이터가 먼저 나옵니다. 이 특징을 줄여서 FIFO(First In First Out)라고 부릅니다.
- 데이터를 집어넣는 enqueue, 데이터를 추출하는 dequeue 등의 작업을 할 수 있습니다.
- 자바스크립트 엔진에서 비동기 함수 실행시 콜백들이 대기열로 들어오는 Task queue가 대표적 예
- 순서대로 처리해야 하는 작업을 임시로 저장해두는 버퍼(buffer)로서 많이 사용된다.
- 너비 우선탐색(BFS), 캐시
class Queue {
constructor() {
this._arr = [];
}
enqueue(item) {
this._arr.push(item);
}
dequeue() {
//배열의 길이만큼 기존 요소들을 앞당겨줘야한다
return this._arr.shift();
}
}
const queue = new Queue();
queue.enqueue(1);
queue.enqueue(2);
queue.enqueue(3);
queue.dequeue(); // 1
Hash 자료 구조
해시함수를 사용하여 키를 해시값으로 매핑하고, 이 해시값을 색인(인덱스) 또는 주소삼아 데이터를 key와 함께 저장하는 자료구조
해시는 '해시함수'라고 하는 함수를 이용해 입력값을 고정길ㅇ ㅣ문자열로 치환
redis가 이 'key' : 'value' 구조를 사용한다.
javascript의 해시테이블
직접 주소 테이블
- 입력받은 value가 곧 key가 되는 데이터 매핑 방식
- 공간의 효율성이 좋지 못하다는 것
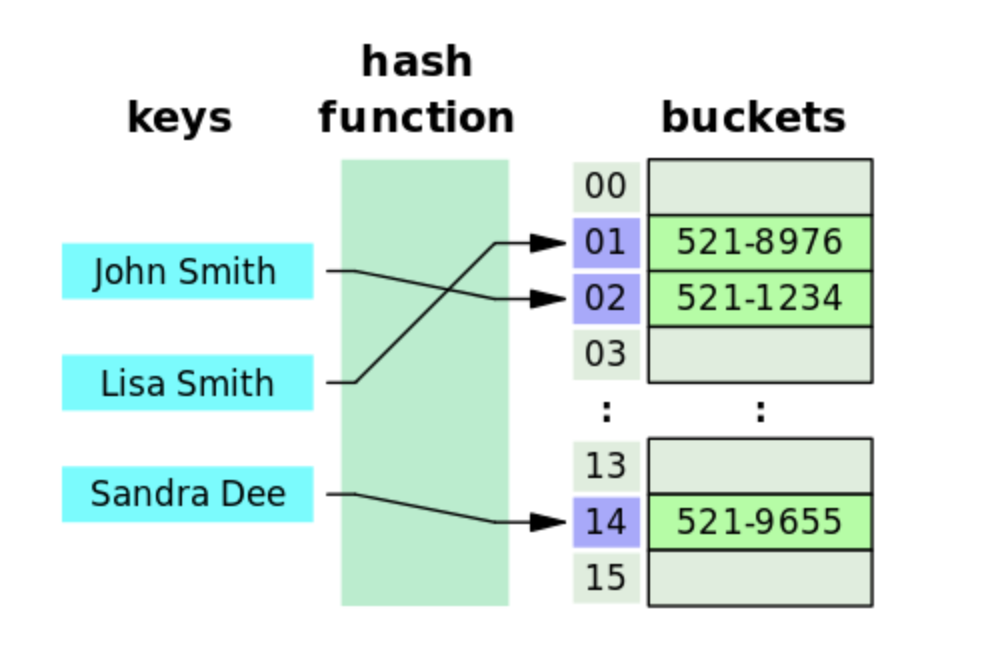
해시테이블
- 값을 바로 테이블의 인덱스로 사용하는게 아니라, 해시 함수에 통과 시켜 사용
- 입력받은 데이터가 인덱스를 받을 수 있도록 매핑, 이 때 함수가 뱉어내는 결과물을 해시라고 함
- 해시 함수는 들어오는 key값을 10으로 나눈 후의 나머지를 반환, 그러나 0~9사이의 값이 나옴
function hashFunction (key) {
return key % 10;
}
console.log(hashFunction(102948)); // 8
console.log(hashFunction(19191919191)); // 1https://bamtory29.tistory.com/entry/Javascript-%ED%95%B4%EC%8B%9C%ED%85%8C%EC%9D%B4%EB%B8%94
B-Tree 자료 구조
이진 트리를 확장해 하나의 노드가 가질 수 있는 자식 노드의 최대 숫자가 2보다 큰 트리구조
1. 노드는 2개이상의 데이터(key)가 들어갈 수 있으며, 항상 정렬된 상태로 저장
2. 내부 노드는 M/2 ~ M개의 자식을 가질 수 있다.
3. 특정 노드의 데이터(key)가 K개라면, 자식 노드위 개수는 K+1개 여야 한다.
4. 특정 노드위 왼쪽 서브 트리는 특정 노드의 key 보다 작은 값들로, 오른쪽 서브트리는 큰 값들로 구성된다.
5. 노드 내에 데이터는 floor(M/2)-1개부터 최대 M-1개까지 포함될 수 있다 ( floor : 내림 함수 Ex-floor(3.7) = 3 )
6. 모든 리프 노드들이 같은 레벨에 존재한다.
Quick / Merge sort
공통점 : 분할정복 방식 알고리즘 이용
| 구분 | 퀵 정렬 | 병합 정렬 |
| 부분 배열의 구획 | 나뉘어진 배열은 여러 비율로 나뉜다. | 배열은 항상 반으로 나뉜다. |
| 최악의 경우 시간복잡도 | ||
| 사용 용도 | 작은 크기의 배열에서 잘 동작 | 어떤 크기의 Dataset에서도 적절히 동작 |
| 효율성 | 작은 크기 Dataset에서는 병합 정렬보다 빠르다. | 큰 Dataset에서는 퀵 정렬보다 빠르다. |
| 정렬 방식 | 내부 정렬 | 외부 정렬 |
| 별도 저장 공간 | 불 필요 | 필요 |
| 참조 지역성 | 좋음 | 퀵 정렬 대비 나쁨 |
| Stable | X(그러나 구현 방식에 따라 가능) | O |
퀵 정렬은 캐쉬에 좀더 Friendly하다. 배열에서 선호된다.
병합정렬은 연결리스트에 좀더 선호 된다.
출처
https://gaemi606.tistory.com/entry/%ED%80%B5-%EC%A0%95%EB%A0%ACQuick-sort
요구사항 명세서
- 소프트웨어가 어떤 문제를 해결하기 위해 제공하는 서비스에 대한 설명과 정상적으로 운영하는데 필요한 제약조건
1. 요구사항의 유형
- 기능 요구사항: 시스템이 무엇을 하는지, 어떤 기능을 하는지에 대한 사항
- 비기능 요구사항: 제약조건, 품질에 관련된 사항
- 사용자 요구사항: 사용자 관점에서 본 시스템이 제공해야 할 요구사항
- 시스템 요구사항: 개발자 관점 (= 소프트웨어 요구사항)
2. 요구사항 개발 프로세스
- 도출 → 분석 → 명세 → 확인
- 요구사항 개발 프로세스가 진행되기 전, 타당성 조사가 선행되어야 함
- 요구공학: 무엇을 개발해야하는지 요구사항을 정의하고, 분석 및 관리하는 프로세스를 연구하는 학문
3. 요구사항 도출
- 시스템, 사용자, 시스템에 개발에 관련된 사람들이 서로 의견을 교환하여 요구사항이 어디에 있는지, 어떻게 수집할 - 것인지 식별하고 이해하는 과정
- 개발자와 고객 사이의 관계 만들어지고 이해관계자(Stakeholder)가 식별
- 기법: 인터뷰, 설문, 브레인스토밍, 프로토타이핑, 유스케이스
4. 요구사항 분석
- 요구사항 중 명확하지 않거나 모호하여 이해되지 않는 부분을 발견하고 이를 걸러내기 위한 과정
- 요구사항 분류, 요구사항 할당, 요구사항 협상, 개념 모델링, 정형 분석
=> UML 모델링, 정형분석(구분 / 의미)
5.요구사항 명세
- 요구사항을 체계적으로 분석한 후 승인될 수 있도록 문서화하는 것
- 기능 요구사항은 빠짐없이 완전하고 명확하게, 비기능 요구사항은 필요한 것만 명확하게 기술 / 잘못된 부분이 확인될 경우 요구사항 정의서에서 추적
6. 요구사항 확인
- 요구사항 명세서가 정확하고 완전하게 작성되었는지 검토
- 고객의 요구사항을 만족시키는지 확인(Validation), 기능을 정확히 수행하는지 검증(Verification)
- 요구사항 검토, 프로토타이핑, 모델 검증, 인수 테이스(알파검사, 베타 검사)
※명세서 작성방법
| 내용 | |
| 요구사항 ID | 요구사항을 식별 할 수 있는 ID |
| 요구사항 명 | 요구사항을 간단하게 설명 할 수 있는 이유 |
| 구분 | 새로운 요구사항인지 기존 시스템에 대한 수정 요구인지 여부 |
| 유형 | 요구사항 유형(시스템 기능, 성능, 데이터, 보안 등) |
| 업무중요도 | 요구사항의 중요도 상/중/하로 구분 |
| 요구사항 | 요구사항 명세서 내용 |
| 관련부서 | 요구사항과 관련된 부사 |
테스트 계획서
명세 기반 테스트 : 요구사항 명세를 테스트 테이스로 만들거 구현하고 있는지 확인
구조 기반 테스트 : SW의 내부논리 흐름에 따라 테스트 케이스로 만들어 구현하고 있는지 확인
경험 기반 테스트 : 테스터 경험을 기반으로 테스트, 요구사항 명세 부족 테스트 시간
테스트 설계 명세서
| 항목 | 설명 |
| 설계 명세서 식별 | 테스트 항목을 식별하고 고유 식별번호 부여 |
| 테스트 대상 특성 | 설계 명세서의 대상인 특성과 그 조합을 기술 |
| 세부 접근방법 | 테스트 계획서에 기술된 방법들을 상세히 명시 |
| 테스트 식별 | 테스트 설계과 관련된 테스트 케이스의 식별자를 열거하고, 이들 각각에 대하여 간략히 설명 |
| 특성의 성공/실패 기준 | 특성 또는 특성의 조합이 합격인지 불합격인지 결정하는데 사용할 기준 명시 |
테스트 케이스 명세서
| 항목 | 설명 |
| 테스트 케이스 명세서 식별자 | 테스트 항목에 대한 고유번호 |
| 테스트 항목 | 테스트 케이스에 의해 테스트를 수행할 항목과 특성을 식별하고, 간략하게 기술 |
| 입력 명세서 | 테스트 케이스의 실행에 필요한 입력을 명시 |
| 출력 명세서 | 테스트 항목에 요구되는 출력과 특성을 명사 |
| 환경 요건 | 테스트 케이스를 실행하는 필요한 하드웨어, 소프트웨어 기타시설 명시 |
| 특정한 절차 요구사항 | 테스트 절차에 대한 특정 제약 사항을 기술 |
| 테스트 케이스간 내부 의존성 | 테스트 케이스 전 반드시 실시되어야 하는 시험 케이스의 식별자를 나열 |
UML
유스케이스 다이어그램
클래스 다이어그램
- 시스템에서 사용되는 객체 타입 정의, 객체지향 시스템 모델링에서 공동적으로 많이 쓰임
- 클래스는 이름, 속성, 연산으로 구성
행위 다이어그램
시퀀스 다이어그램
콜라보레이션 다이어그램
클래스 다이어그램
컴포넌트 다이어그램
Process/Thread
프로그램 : 파일이 저장장치에 저장되어 있지만, 메모리에는 올라가지 않는 상태
어떠한 작업을 위해 실행 할 수 있는 파일
프로세스 : 운영체제로 부터 자원을 할당받는 작업의 단위, 메모리에서 올라와 실행되고 있는 프로그램의 인스턴스
스레드 : 할당 받은 자원을 이용하는 실행의 단위, 프로세스내 여러개 존재
프로세스 내에서 stack만 할당 받고 code, data, heap 영역은 공유
ex) 어플리케이션 하나가 프로세스고, 그 안의 분기 처리가 스레드가 된다.
멀티 프로세스
- 하나의 프로그램을 여러 프로세스로 구성, 각 프로세스가 하나의 작업을 처리
- 다른 프로세스에 영향을 끼치지 않는다.
- 단점 : Context Switching 비용 발생
멀티 스레드
- 프로그램을 여러개의 스레드로 구성하고, 각 쓰레드가 작업을 처리, 실행 속도 향상으로 처리 비용 감소
- 단점 : 디버깅 어려움, 동기화 이슈 발생, 하나의 스레드에 문제가 생기면 프로세스에 영향이 끼침
쓰레드 세이프
- 여러 쓰레드가 동시에 사용되어도 안전하다.
Context Switching
CPU에서 여러 프로세스를 돌아가면서 작업을 처리하는 것
동작중인 프로세스가 대기를 하면서 해당 프로세스의 상태를 보관하고 대기하다가 다시 실행시 복구하는 비용 의미
CPU 레지스터, RAM과 CPU 사이의 캐시 메모리가 초기화 되기 때문에 오버헤드가 크다
참고 :
Kernel
커널(kernel)은 컴퓨터 운영 체제의 핵심이 되는 컴퓨터 프로그램으로, 시스템의 모든 것을 완전히 통제
운영체제의 핵심 부분
보안 - 컴퓨터의 하드웨어와 프로세스의 보안을 책임진다.
자원관리 - 한정된 시스템 자원을 효율적으로 관리
객체지향
nodejs javascript 싱글스레드인데 비동기적인 이유?
싱글스레드는 stack을 하나밖에 가지지 못한다.
비동기 : 먼저 실행된 코드의 작업이 끝나기전 나중 실행된 코드의 작업이 끝남
Design Pattern
개발방법론
E-R Diagram
ODBC
'CS지식' 카테고리의 다른 글
| 엔드 포인트 보안이란? (0) | 2022.07.02 |
|---|---|
| 유저 모드 커널 모드 간단정리 (0) | 2022.06.28 |